ETL and How it Changed Over Time
Modern world data and its usage has drastically changed
when compared to a decade ago. There is a gap caused by the traditional
ETL processes when processing modern data. The following are some of the
main reasons for this:
- Modern data processes often include real-time streaming data, and organizations need real-time insights into processes.
- The systems need to perform ETL on data streams without using batch processing, and they should handle high data rates by scaling the system.
- Some single-server databases are now replaced by distributed data platforms (e.g., Cassandra, MongoDB, Elasticsearch, SAAS apps), message brokers(e.g., Kafka, ActiveMQ, etc.) and several other types of endpoints.
- The system should have the capability to plugin additional sources or sinks to connect on the go in a manageable way.
- Repeated data processing due to ad hoc architecture has to be eliminated.
- Change data capture technologies used with traditional ETL has to be integrated to also support traditional operations.
- Heterogeneous data sources are available and should look at maintenance with new requirements.
- Sources and Target endpoints should be decoupled from the business logic. Data mapper layers should allow new sources and endpoints to be plugged in seamlessly in a manner that does not affect the transformation.
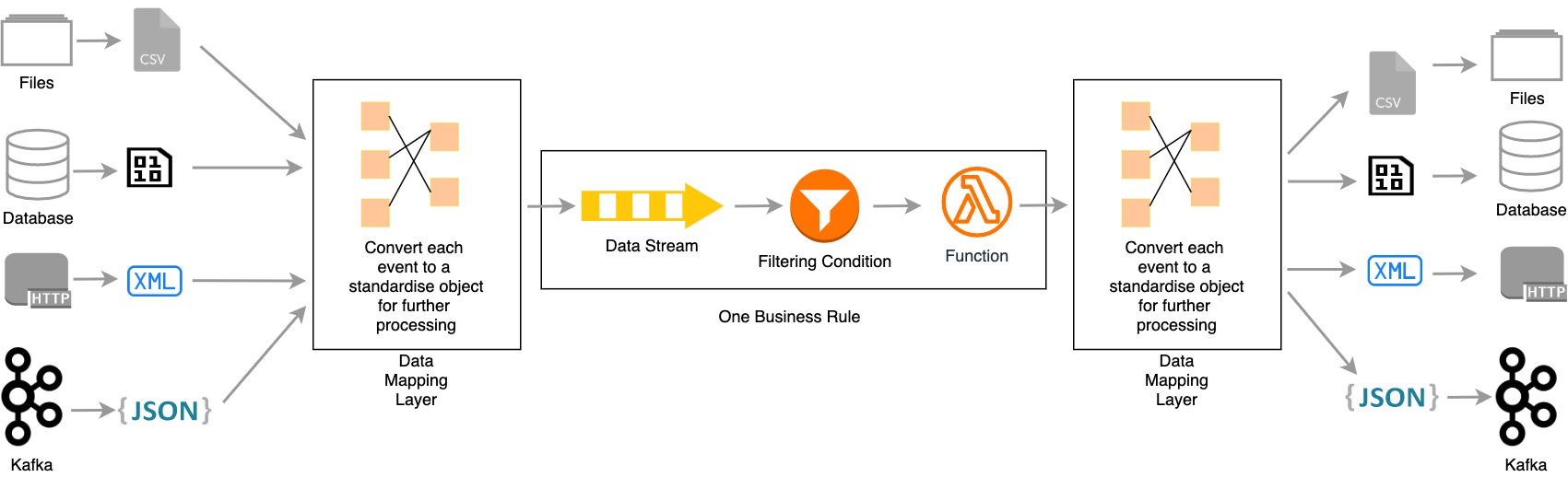
Data mapping layer - Received data should be standardized before transformation (or executing business rules).
- Data should be converted to specific formats after transformation and before publishing to endpoints.
- Data cleansing is not the only process defined in
transformation in the modern world. There are many business requirements
that organizations need to be fulfilled.
- Current data processing should use filters, joins, aggregations, sequences, patterns, and enriching mechanisms to execute complex business rules.
Read full article >>>
Comments
Post a Comment