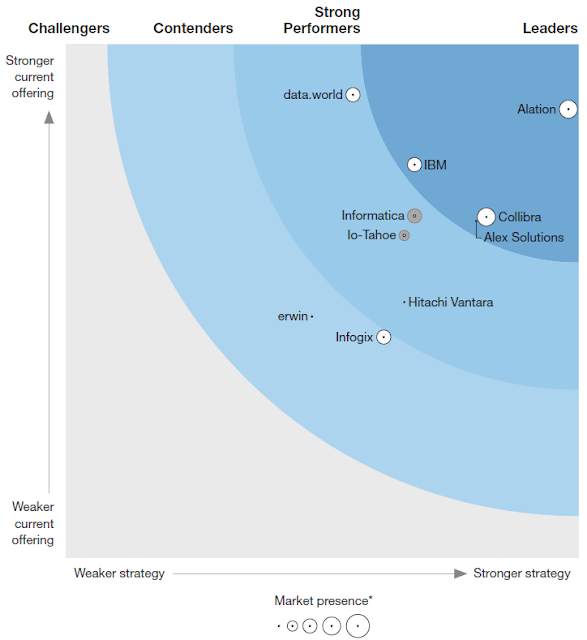
The Growing Importance of Metadata Management Systems

As companies embrace digital technologies to transform their operations and products, many are using best-of-breed software, open source tools, and software as a service (SaaS) platforms to rapidly and efficiently integrate new technologies. This often means that data required for reports, analytics, and machine learning (ML) reside on disparate systems and platforms. As such, IT initiatives in companies increasingly involve tools and frameworks for data fusion and integration. Examples include tools for building data pipelines, data quality and data integration solutions, customer data platform ( CDP ) , master data management , and data markets . Collecting, unifying, preparing, and managing data from diverse sources and formats has become imperative in this era of rapid digital transformation. Organizations that invest in foundational data technologies are much more likely to build solid foundation applications, ranging from BI and analytics to machine learn...