Gartner Hype Cycle for Data Science and Machine Learning, 2017
The hype around data science and machine learning has increased from already high levels in the past year. Data and analytics leaders should use this Hype Cycle to understand technologies generating excitement and inflated expectations, as well as significant movements in adoption and maturity.
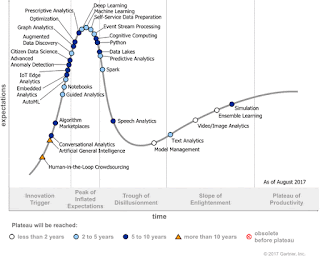 The Peak of Inflated Expectations is crowded and the Trough of Disillusionment remains sparse, though several highly hyped technologies are beginning to hear the first disillusioned rumblings from the market. In general, the faster a technology moves from the innovation trigger to the peak, the faster the technology moves into the trough as organizations quickly see it as just another passing fad.
The Peak of Inflated Expectations is crowded and the Trough of Disillusionment remains sparse, though several highly hyped technologies are beginning to hear the first disillusioned rumblings from the market. In general, the faster a technology moves from the innovation trigger to the peak, the faster the technology moves into the trough as organizations quickly see it as just another passing fad.
The Hype Cycle
 The Peak of Inflated Expectations is crowded and the Trough of Disillusionment remains sparse, though several highly hyped technologies are beginning to hear the first disillusioned rumblings from the market. In general, the faster a technology moves from the innovation trigger to the peak, the faster the technology moves into the trough as organizations quickly see it as just another passing fad.
The Peak of Inflated Expectations is crowded and the Trough of Disillusionment remains sparse, though several highly hyped technologies are beginning to hear the first disillusioned rumblings from the market. In general, the faster a technology moves from the innovation trigger to the peak, the faster the technology moves into the trough as organizations quickly see it as just another passing fad.
This Hype Cycle is especially relevant to data and analytics leaders, chief data officers, and heads of data science teams who are implementing machine-learning programs and looking to understand the next-generation innovations. Technology provider product marketers and strategists who offer data science platforms or enterprise applications with embedded advanced analytics can use this Hype Cycle for product roadmap planning. Individuals who closely collaborate with data scientists or who have ambitions to acquire data science and machine-learning skills will also benefit from reading it.
Data science and machine learning are nothing new, but several high-level trends continue to push technologies into the spotlight and generate attention and enthusiasm:
- Growing interest (and hype) around artificial intelligence (AI), fueled by vendor marketing combined with the understandable but erroneous conflation of AI with data science and machine learning.
- The data science and machine-learning talent shortage, and efforts to combat it with education, upskilling and smarter tools using more automation.
- Increases in computing power and availability of advanced system architectures, in-memory computing and storage, as well as more powerful and efficient chipsets in a highly scalable, cloud-based architecture. These advances have also fueled the hype and interest around deep learning.
- The explosion in popularity of open-source tools and libraries for data science and machine learning. The data science and machine-learning market is one of the most vibrant and collaborative technology market that strongly embraces open-source technologies.
- Faster model building and deployment, along with model management capabilities that can handle thousands of models in production and the other demands of operationalization.
Significant year-over-year movements by several technologies on the Hype Cycle reflect these trends. For example:
- Cognitive computing has reached the Peak of Inflated Expectations due to the pervasive promotion of the term by major vendors seeking differentiation in the AI marketplace.
- Prescriptive analytics has reached the Peak of Inflated Expectations, while predictive analytics is slightly ahead on the cycle and on the verge of entering the Trough of Disillusionment.
- Python has moved past the Peak of Inflated Expectations; while it is still highly hyped, it is becoming one of the programming language standards for data scientists and will move quickly through the Trough of Disillusionment.
- Spark and data lakes are on the verge of entering the Trough of Disillusionment.
- Model management has moved through the Trough of Disillusionment and is beginning to climb the Slope of Enlightenment as organizations better understand how to deploy and manage models in production.
- Guided analytics, smart data discovery, and citizen data science are all steadily rising the slope toward the Peak of Inflated Expectations as a way of addressing the data scientist skill gap.
Figure 1 shows Gartner's Hype Cycle for Data Science and Machine Learning. Figure 2 displays the associated Priority Matrix, which presents a snapshot of each technology arranged in relation to two dimensions: maturity and business impact.
The new entrants in this year's Hype Cycle attest to the strong interest in using AI technologies to augment human decision making.
New Entrants
- Human-in-the-loop crowdsourcing: This is the complementary use of humans and algorithm-based automation to solve a problem or perform a task, where the human input further improves the automated AI or data management solution.
- Artificial general intelligence: General-purpose AI can handle a very broad range of use cases compared to today's special-purpose AI technologies that are limited to specific uses.
- Conversational analytics: This technology reflects using personal digital assistants or mobile devices to enable users to ask voice or text questions of their data and receive back a natural language and visual analysis of the most statistically relevant and actionable insights.
- Embedded analytics: Like more traditional forms of analytics, data science and machine learning are increasingly being embedded into enterprise applications and other business tools to be consumed by other end users beyond just data scientists and analytics professionals.
Name Changes
- Deep learning (formerly deep neural nets): The new name, though less precise, reflects the most common and accepted terminology.
- IoT edge analytics (formerly edge analytics): The new name reflects the growing need to deploy analytics and machine learning closer to Internet of Things (IoT) devices.
(provided by Microsoft here)
Comments
Post a Comment