Emerging Architectures for Modern Data Infrastructure
As an industry, we’ve gotten exceptionally good at building large, complex software systems. We’re now starting to see the rise of massive, complex systems built around data – where the primary business value of the system comes from the analysis of data, rather than the software directly. We’re seeing quick-moving impacts of this trend across the industry, including the emergence of new roles, shifts in customer spending, and the emergence of new startups providing infrastructure and tooling around data.
In fact, many of today’s fastest growing infrastructure startups build products to manage data. These systems enable data-driven decision making (analytic systems) and drive data-powered products, including with machine learning (operational systems). They range from the pipes that carry data, to storage solutions that house data, to SQL engines that analyze data, to dashboards that make data easy to understand – from data science and machine learning libraries, to automated data pipelines, to data catalogs, and beyond.
Due to the energy, resources, and growth of the data infrastructure market, the tools and best practices for data infrastructure are also evolving incredibly quickly. So much so, it’s difficult to get a cohesive view of how all the pieces fit together. And that’s what we set out to provide some insight into.
We asked practitioners from leading data organizations: (a) what their internal technology stacks looked like, and (b) whether it would differ if they were to build a new one from scratch.
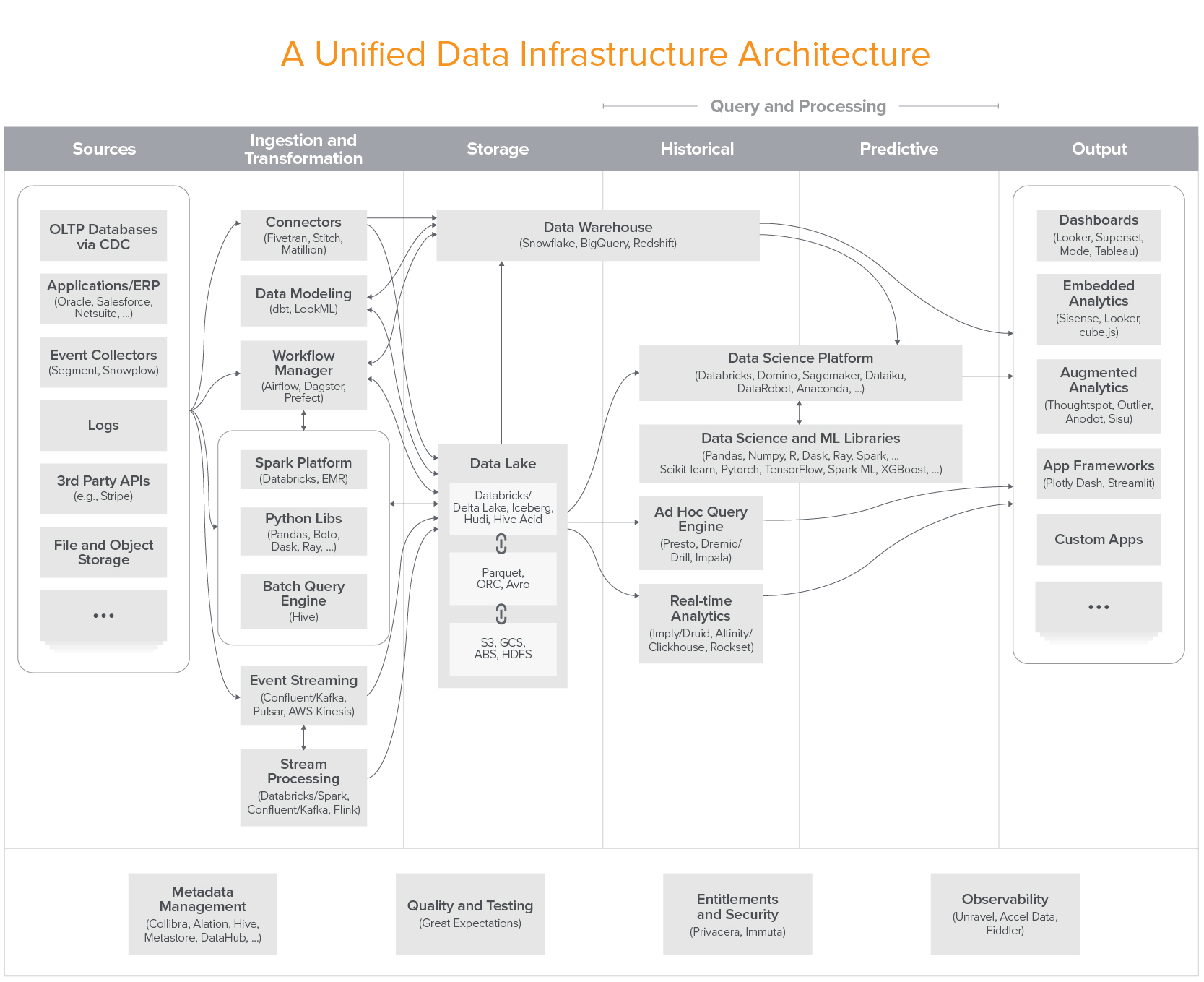
There is a lot going on in this architecture – far more than you’d find in most production systems. It’s an attempt to provide a full picture of a unified architecture across all use cases. And while the most sophisticated users may have something approaching this, most do not.
The rest of this post is focused on providing more clarity on this architecture and how it is most commonly realized in practice.
Comments
Post a Comment