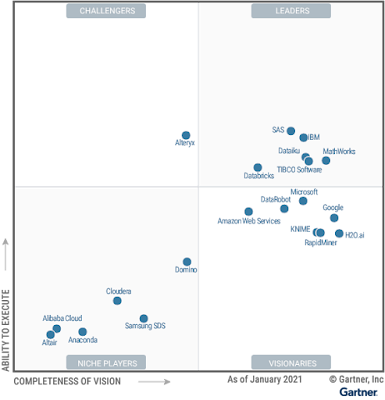
Dec 2021 Gartner Magic Quadrant for Cloud Database Management Systems

Database management systems continue their move to the cloud — a move that is producing an increasingly complex landscape of vendors and offerings. This Magic Quadrant will help data and analytics leaders make the right choices in a complex and fast-evolving market. Strategic Planning Assumptions By 2025, cloud preference for data management will substantially reduce the vendor landscape while the growth in multicloud will increase the complexity for data governance and integration. By 2022, cloud database management system (DBMS) revenue will account for 50% of the total DBMS market revenue. These DBMSs reflect optimization strategies designed to support transactions and/or analytical processing for one or more of the following use cases: Traditional and augmented transaction processing Traditional and logical data warehouse Data science exploration/deep learning Stream/event processing ...