Confluo: Millisecond-level Queries on Large-scale Live Data
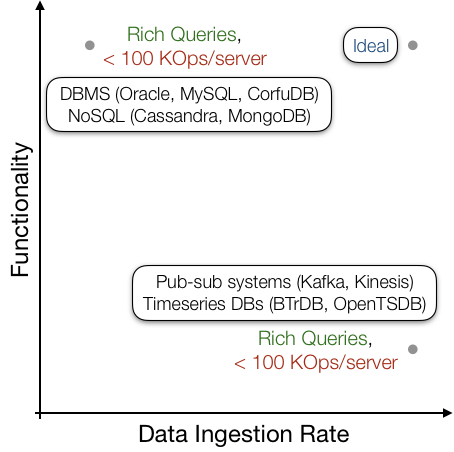
Confluo is a system for real-time distributed analysis of multiple data streams. Confluo simultaneously supports high throughput concurrent writes, online queries at millisecond timescales, and CPU-efficient ad-hoc queries via a combination of data structures carefully designed for the specialized case of multiple data streams, and an end-to-end optimized system design.
 We are excited to release Confluo as an open-source C++ project, comprising:
We are excited to release Confluo as an open-source C++ project, comprising:- Confluo’s data structure library, that supports high throughput ingestion of logs, along with a wide range of online (live aggregates, conditional trigger executions, etc.) and offline (ad-hoc filters, aggregates, etc.) queries, and,
- A Confluo server implementation, that encapsulates the data structures and exposes its operations via an RPC interface, along with client libraries in C++, Java and Python.
We have evaluated Confluo for several different application scenarios, including:
- A network monitoring and diagnosis framework, where Confluo is able to execute thousands of triggers and tens of filters at line rate (for 10Gbps links) on a single core.
- A time-series database, where Confluo achieves 2-20x higher throughput, 2-10x lower latency for inserts, and 1.5x-5x higher throughput, 5-20x lower latency for time-range queries compared to state-of-the-art time-series databases: CorfuDB, TimescaleDB, and BTrDB.
- A pub-sub system, where Confluo outperforms Apache Kafka by a factor of 4-10x for publish-subscribe throughput.
Comments
Post a Comment