2019 Was the Year Data Visualization Hit the Mainstream
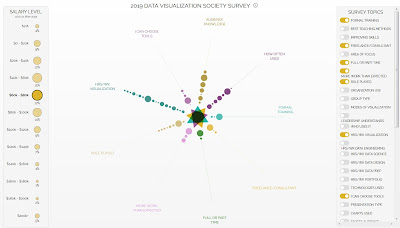
There’s always something going on in the field of data visualization but until recently it was only something that people in the field noticed. To the outside world, beyond perhaps an occasional Amazing Map®, Tufte workshop or funny pie chart, these trends are invisible. Not so in 2019, where data visualization featured prominently in major news stories and key players in the field created work that didn’t just do well on Dataviz Twitter but all over. 2019 saw the United States President amend a data visualization product with a sharpie. That should have been enough to make 2019 special, but the year also saw the introduction of a data visualization-focused fashion line, a touching book that uses data visualization to express some of the anxieties and feelings we all struggle with, as well as the creation of the first holistic professional society focused on data visualization. Original Article >>>





















